

Бум 2022 от Сhat GPT породил в 2023 году повышенный интерес ко всему, что связанно с нейросетями. Интерес коснулся и генерации изображений. Теперь еще больше художников прибегают к помощи сервисов или приложений для создания задников, рисования интерьера, отбора референсов или даже смены гардероба (напоминаю, что ушедшая из России Canva представила инструмент изменения внешнего вида одежды - что на фото, что на изображениях). Другой случай произошел на выставке Sony World Photography Awards. Фотограф Борис Эльдагсен отказался от премии в $5000. Он признался, что представленный на конкурс снимок создавался с помощью нейросетей, поэтому отказывается от получения премии. «Сгенерированные изображения и фотографии не должны конкурировать друг с другом в рамках одной премии. Это разные вещи», — отметил Эльдагсен.

Фрагмент снимка берлинского фотографа Б.Эльдагсена «Псевдомнезия: электрик»/ Eldagsen.com
Поэтому интерес к созданию изображений через такие сервисы вполне объясним. Теперь немного обратимся к теории. Какие бывают нейросети?
1. Генеративно-состязательные сети. К таковым относят NVidia GAN. Такую нейросеть можно запустить на компьютере, но это достаточно трудоёмкий процесс. Они состоят из двух компонентов: генератора и дискриминатора. Генератор создает изображения, а дискриминатор оценивает, насколько реалистичен результат. GAN-нейросети вполне способны создавать правдоподобные массивы вроде пейзажей - фото или игровых.
2. Автоэнкодеры - нейросети, которые создают изображения, используя кодировщик и декодировщик. Автоэнкодеры могут использоваться для создания стилизованных изображений и для реставрации изображений с повреждениями. Автоэнкодеры используются в некоторых смартфонах в камерах. Примером автоэнкодера как сервиса является DeOldify - проект на GitHub, который используется для восстановления черно-белых фотографий в цветные.
3. Рекуррентные нейросети (RNN) - это нейросети, которые используются для создания последовательных изображений, таких как анимации, видео и тексты. RNN состоят из повторяющихся блоков, которые могут запоминать предыдущее состояние и использовать его для создания следующего изображения в последовательности. Примером является любой современный сервис перевода или голосовой помощник (Алиса, например), сервис грамотности вроде Grammarly.
4. Свёрточные нейросети (CNN) - это нейросети, которые используются для обработки изображений. Они могут использоваться для создания фотореалистичных изображений, а также для распознавания образов и классификации изображений. YOLO (You Only Look Once) - сверточная нейронная сеть для обнаружения объектов на изображениях в реальном времени. 5. Трансформеры - это нейросети, которые используются для обработки последовательностей, таких как текст или звук. Они могут использоваться для создания стилизованных изображений, таких как картинки в стиле живописи. Один из наиболее известных примеров нейросети-трансформера - это модель GPT (Generative Pre-trained Transformer), разработанная командой OpenAI. GPT - это серия сверточных нейросетей, которые используют механизм трансформера для генерации текста. Она была обучена на огромном объеме текстовых данных, включая Википедию и ряд других источников, и может генерировать связный текст на любую тему.
Некоторые нейросети представляют собой комбинацию этих опций, а что касается современных сервисов, то они могут сочетать в себе несколько функций.
По видам нейросетей по функционалу с изображениями выделяют "текст в фото" (вы пишете текстовой запрос, а вам выдают изображение), "фото+текст" (отправляете фото, затем текст, а потом нейросеть обрабатывает изображение по запросу) "смешивание фото"(смешивание атрибутов двух фотографий), "вариация фото" (вы отправляете фотографию, а нейросеть перерисовывает распознанное в другой композиции).
Теперь, собственно, те инструменты, которыми я пользую лично:
Upscale AI
1.- апскейлингом называют увеличение масштаба изображения. Upscale AI нейросетка увеличивает ваше изображение в размерах без потери качества в 2-4 раза. Это нужно если ваше изображение слишком ма́ло. Не рекомендую апскейлить фотографии, которые отправляете на обработку в перечисленные ниже сервисы кроме совсем уж маленьких размеров. Некоторые нейросети из-за ограниченного времени обработки, не успевают "пройтись" по всему изображению, в результате чего у нас получаются размытые лица на втором и третьем плане). Это можно использовать, если у вас есть собственная машинная обработка (о которой я тоже расскажу в одной из частей).
Шедевриум
Шедевриум - нейросеть, которая генерирует по текстовому запросу от Яндекса. На момент написания статьи, находится в бета-версии. Шедевриум по умолчанию использует генерацию в стиле крупных мазков. Шедевриуму нельзя затрагивать чувствительные темы, как и нельзя генерировать реальных личностей, но можно создавать амплуа и популярные образы. Плюс, есть способ, как обходить этот запрет, по крайней мере, это связано с актерами - писать с ошибкой ("Маддс Миккельсе н" ), переставлять буквы (Кенедикт Бамбербэтч), менять буквы (Хлоя Моретz):
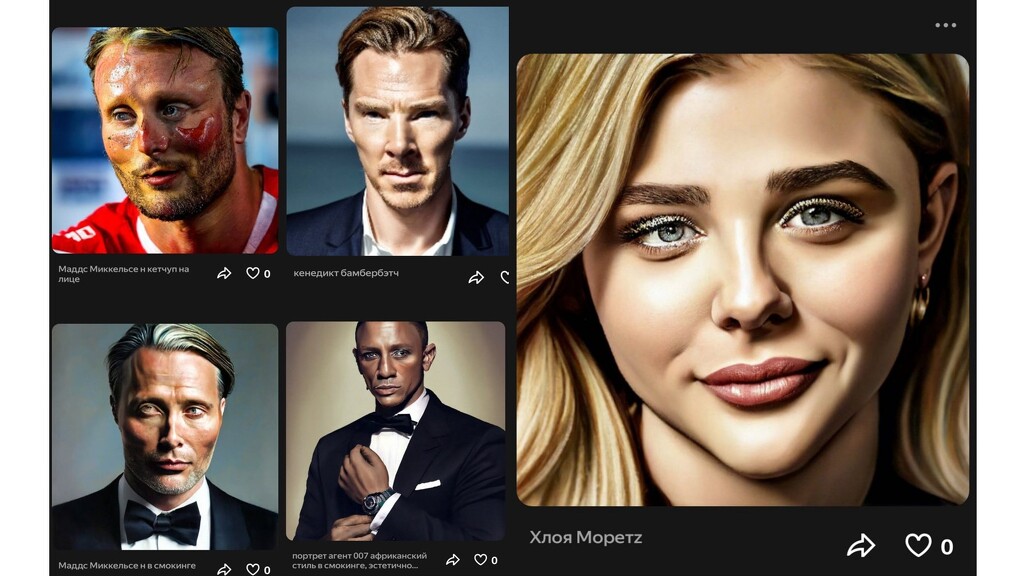
Не бейте, дяденьки из Яндекса, это не баг, а фича.
В целом, Шедевриум достаточно шустрый, можно уйти в другое приложение, чтобы заниматься своими делами. Шедевриум сделает все за минуту или две - достаточно позже заглянуть туда. Вдобавок, он сделан на манер социальной сети и там уже есть своё комьюнити.
По качеству генераций может казаться, что Шедевриум рисует не очень качественно. Но это не так - даже при простых промтах, нейросеть способна рисовать красивые пейзажи, а чем больше уточнений, тем симпатичнее получается результат. Механика соцсети тут уместна. К тому же, при наборе промта (например, "северное сияние в тропиках"), можно нажать на кнопку вопросительного знака в круге, где есть список настроек, уточняющих стиль. Как и во многих нейросетях, часть этого списка похоже на настройки фотоаппарата (вплоть до того, что работает запрос "тилт-шифт").

Пейзажи из Шедевриума можно использовать как потенциальные задники и для дальнейших обработок. Или как основы для открыток.
Kandinsky
Kandinsky 2.1 - нейросеть от Сбера. У нее есть вариация на сайте fusionbrain.ai, или rudalle.ru. Интегрированный в телеграм-бот, Кандинский - это очень удобная система. У Кандинского в телеграм есть сразу несколько моделей работы:
● Текст в изображение - ну тут понятно, чем конкретнее промт, тем больше конкретность.
● Смешивание изображений - когда вы прикрепляете два фото и нейросеть работает с ними.
● Фото + текст - вы отправляете фото, а затем пишете к нему описание и нейросеть рисует вам указанную деталь или перерабатывает стиль.

Результаты работы Kandinsky 2.1 в разных стилях - 4 основных стиля (аниме, 4k, артстейшн, без стиля) - и вариации работы - объединение с текстовым запросом и другим изображением
● Вариация картинки меняет ракурс или композицию. Вот, например, что получается, если сделать вариацию из объединения двух фото:

Вариация для объединенного фото. В целом, вы можете отправить даже туда свое фото, но результат может быть забавным и переработанным.
В Ru-Dalle на текущий момент идет только генерация текста из картинок, нет настроек, только промты. А вот Fusionbrain.ai с Кандинским 2.1 похож на редактор с огромным количеством вариаций стиля, которых аж 24: Без стиля, Аниме, Детальное фото, Киберпанк, Кандинский, Айвазовский, Малевич, Пикассо, Гончарова, Классицизм, Ренессанс, Картина маслом, Рисунок карандашом, Цифровая живопись, Средневековый стиль, Советский мультфильм, 3D-рендеринг, Мультфильм, Студийное фото, Портретное фото, Мозаика, Иконопись, Хохлома, Новый год.
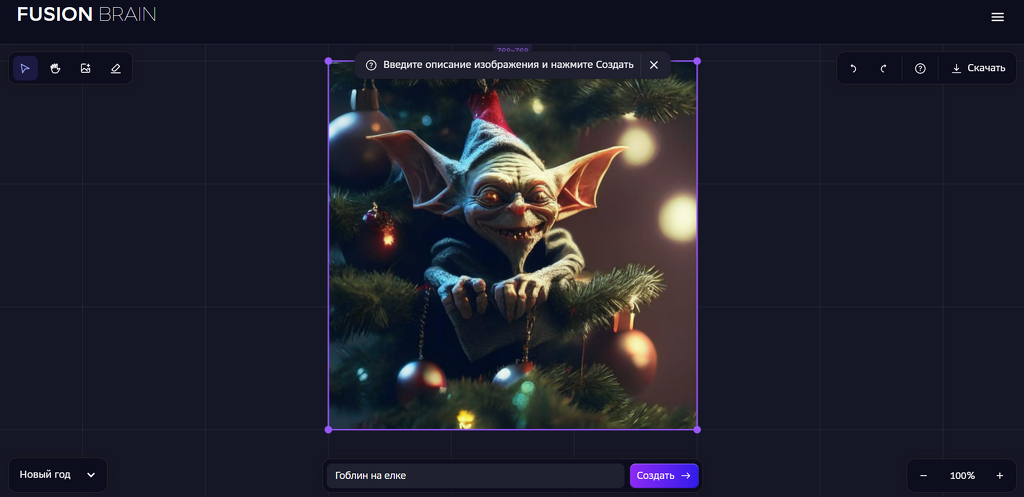
Процесс создания простых изображений в этой программе осуществлятся текстовыми запросами, а сгенерированное изображение отображается внутри синей рамки. Размер и положение рамки могут быть изменены для создания единого холста. Давайте рассмотрим это на примере: выбрав режим "Новый Год", мы можем создавать изображения, передвигая рамку и нажимая кнопку "Создать", чтобы сгенерировать новое изображение. При этом важно учитывать, что если рамка пересекает ранее созданные изображения, то они не будут включены в генерацию нового изображения. Мы также можем изменять описание и стиль на каждом шаге, что дает возможность создавать разнообразные изображения в соответствии с вашей фантазией:
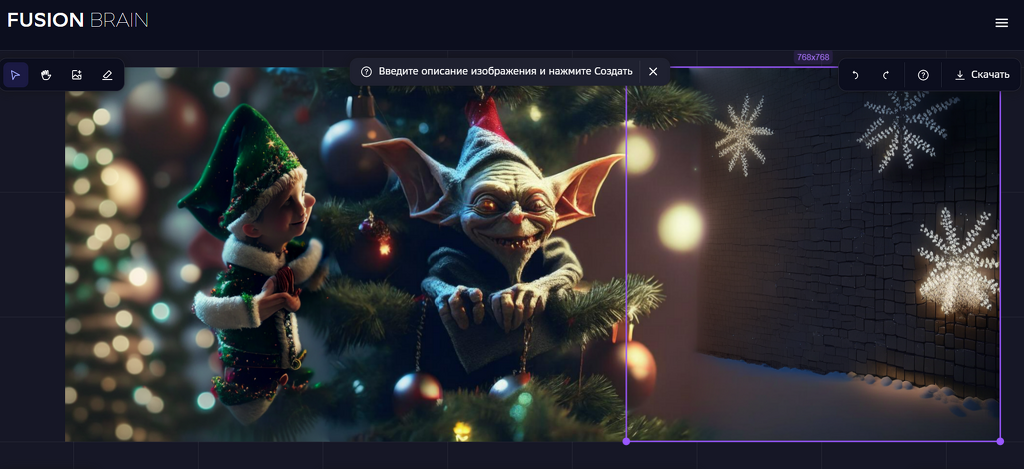
Генерация картинок в fusionbrain происходит по квадратам. Можно смешивать стили и добавлять свои фото, менять размер рамки.
Инструменты Сбера хоть и не создают очень красивые картинки как в Шедевриуме, но ими тоже можно пользоваться для созданий крутых коллажей, необычных ремиксов собственных фотографий.
Meitu
Meitu AI - это одна из рубрик крутейшего китайского приложения Мейту (美图 красивые изображения). В нем можно изменять геометрию лиц, бровей, добавлять детали на изображения и ретушировать на достойном уровне и даже удалять водяные знаки. Помимо этого, Мейту способен быстро выдавать 5 вариаций генерации, что для других приложений и платформ - весьма завидный результат.
Для использования достаточно просто выбрать инструмент и загрузить фотографию из галереи. Результат, однако, имеет нюанс:

Мы использовали фотографию агента 007 в африканском стиле (из Шедевриума) и он из-за обработки поменял расу. Да, это нужно иметь в виду, что у Мейту результаты будут в аниме стиле или будут нести азиатские черты лица.
Для открыток - взять пейзаж из Шедевриума или Кандинского, который кажется грубоватым и прогнать через инструмент. Мейту хорош именно как способ "доработать напильником" грубоватый результат из других нейросетей.

Открытка из Meitu. Изначально это был большеглазый и весьма грубонарисованный кролик из Шедевриума. А сейчас даже хочется дать ему морковки.
В следующей части я расскажу о других нейросетях, которые тоже использую для рисования.😉





