

В нашем информационном пространстве уже хватает инструкций о пользе этой компьютерной программы. Бот пишет код, стихи, seo-статьи, сценарии, книги, рекламный контент, дипломы, сдаёт экзамен для получения медицинской лицензии в США.. С помощью программ на основе искусственного интеллекта создают игровые приложения и сайты, где иллюстрации генерирует нейросеть MidJourney.
Везде восхищённые отзывы и примеры, как бот можно использовать для автоматизации бизнес-процессов и различных маркетинговых задач. Но не будем забывать что, это всего лишь созданная человеком и им же управляемая программа.
Немного истории
Технологии в области автоматизации решения интеллектуальных задач возникли ещё в 50-х годах прошлого века. А термин «искусственный интеллект» появился на конференции по машинному обучению в Дартмутском колледже, штате Нью-Гэмпшир, США.
Тогда в 1965 году громкие заявления вроде: «Машины смогут через 20 лет делать любую работу, которую делает человек» — привлекали новые правительственные и частные вложения. Одним из наиболее значимых спонсоров было управление исследовательских центров министерства обороны США (ARPA), отвечающее за разработку новых технологий для применения в военной сфере.
Но шло время, а пока все ожидали результатов, наступила инвестиционная зима. Финансирование отрасли искусственных нейронных сетей значительно сократили, потому что машины со среднестатистическим человеческим интеллектом, как было обещано, не появились.
Какое-то время технологии использовались спецслужбам, а потом стали открыты и для коммерческого использования.
Сейчас революционные технологии доступны широким массам. Это «второе пришествие Христа», или ещё нет? Чтобы лучше понимать, какие-то отрасли претерпят изменения, давайте сначала разберёмся, как работает алгоритмический «текстомёт» и интеллект ли это.
Генеративный предварительно обученный трансформер — так дословно расшифровывается аббревиатура GPT.Усовершенствованная языковая модель GPT-3.5 всё ещё предсказывает следующие слова, дописывая текст.
Познакомившись с генератором текста в начале января, я была заинтригована и очень торопилась найти боту хоть какое-то практическое применение. Правда, исследуя программу шаг за шагом, я медленно теряла интерес...

О токенах и запросах на русском языке
Людям, не связанным с программированием будет сложно понять этапы вычленения основного смысла и выдачу ответа похожего на осмысленную речь. Очень подробно об этом уже написали, например, тут.
Преобразуя слова в токены(элементы), а токены в векторы и далее, разбираются слои, выполняется анализ, как каждое слово в запросе соотносится с другим. Потом данные объединяются, соотносятся с параметрами, а модель выбирает лучшую последовательность для ответа.
При обработке текста бот представляет каждый его элемент в виде вектора, набора чисел и производит математические операции, что позволяет определить смысловое содержание запроса.
Проще говоря, трансформер, разобрав лексическую конструкцию на токены, пропускает их через «чёрный ящик» и выдаёт новый набор токенов.
Что такое токен? Токен — это единица информации для нейросети, как бит для компьютера.Возьмём запрос «How to repair a cut in a leather couch». Предложение содержит 9 токенов и 38 символов.
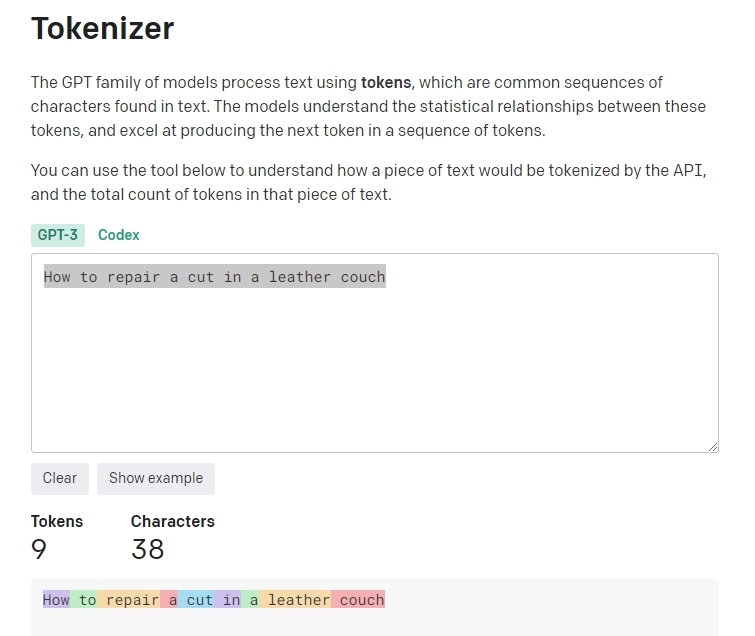
Токены в английском языке — это сочетания символов, часто совпадающие с короткими частями речи. Где один токен часто соответствует примерно 4-м символам обычного текста, это — где-то 3⁄4 слова, таким образом, 100 токенов ~= 75 слов.
Сформулируем такой же запрос на русском: «Как починить порез на кожаном диване». В этом случаем получаем 39 токенов и 36 символов.
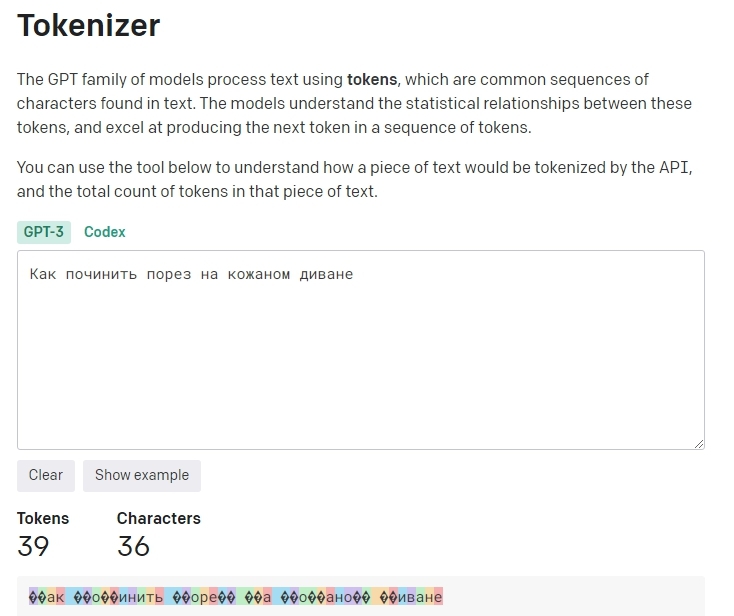
С русским языком токенограма ОpenAI работает по-другому, в данном случае на упаковку 36 символов требуется 39 токенов. При токенизации кириллицы один токен не равен короткому слову, и даже не всегда одному символу, что делает обработку запросов на русском языке дороже. Каждые использованные 1000 токенов в трансформере Text-davinci-003 от OpenAI стоят 0,02 доллара.
Удивительно, что разбирая предложения на буквы и дробные букв, бот генерирует осмысленные ответы на русском языке.
Интересно, что при написании вопроса на транслите: "Kak pochinit’ porez na kozhanom divane" мы получим 16 токенов и 38 символов.
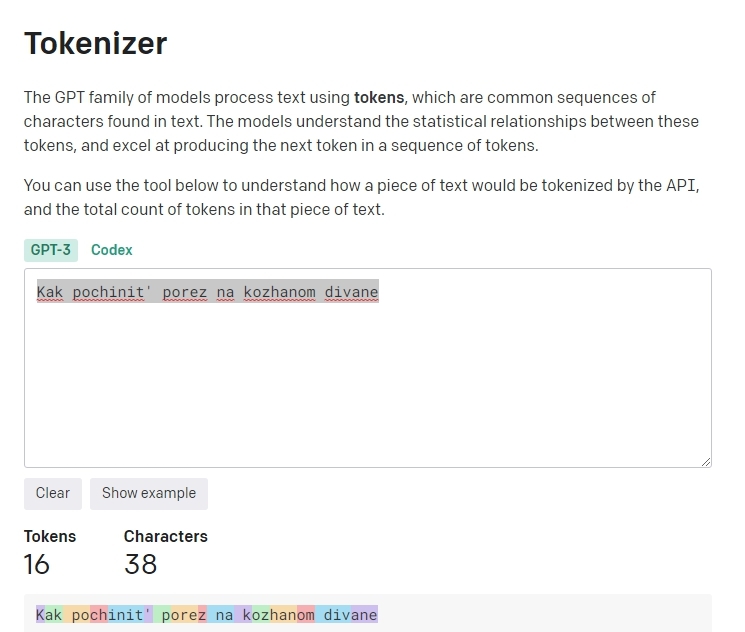
Для ряда языков, токены не декодируются по отдельности, видимо, тут кроется ответ.
ChatGPT оптимизировали и обучали на английском, а доля русского текста, по некоторым данным (разработчики не раскрывают информацию) составляет менее 1%.
Пользователи продолжают спорить, генерирует ли бот текст на русском или сначала переводит на английский, вычленяет токены, формирует новые, а потом переводит результат обратно.
Встречаются разные мнения. Задавая боту вопрос об алгоритмах работы с текстом, можно получить противоречащие друг другу ответы. Вот, что генератор текста ответил мне, но этому верить нельзя.

Машинный перевод за последнее десятилетие значительно улучшился. Раньше тот же Google Translate работал на основе рекуррентных нейронных сетей, которые последовательно переводили каждое слово, и в таком же порядке составлял из них предложения. Сейчас технология перевода изменилась: алгоритмы учитывают всё предложение полностью, анализируют контекст.
Такой метод обработки текста, под названием «трансформеры» — основа языковой модели.
Эта технология позволяет боту работать с другими языками, переводя текст на входе и на выходе и разбирая только английские запросы на токены.
При запросе: «Дай определение женщине» сначала на русском, а потом на английском(please define a woman), получаем идентичные ответы.
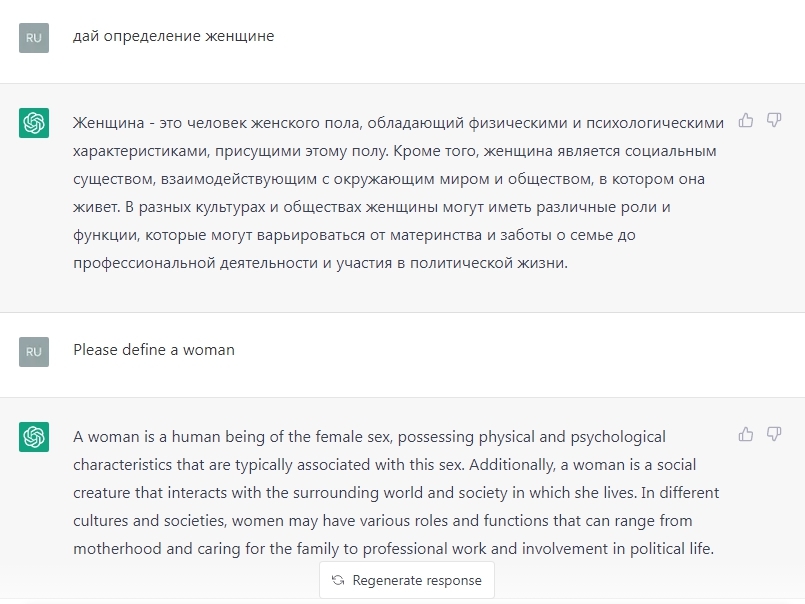
Если вы переведёте текст с английского на русский через Гугл переводчик, то получите такой же текст слово в слово.
Заключение
Бот не выдаёт осмысленных ответов, сути вопроса не понимает. При каждом запросе полученная информация может отличаться. Модель создает похожее, переиначивая уже созданное. Она не обладает сознанием, за пределы «изученного» не выйдет и не сможет сделать открытие.
Накладывая одно изображение на другое, меняя прозрачность, размывая пиксели, играя с фильтрами в соответствии с нашими задачами, мы в результате получаем новый слепок. Примерно так выглядит алгоритм создания уникального контента.
Неизвестно какие изменения претерпят алгоритмы трансформеров в будущем. Сейча тестируя нейронную сеть ChatGPT, формируя запрос на русском языке, мы получаем качественный машинный перевод по нейро-сетевой технологии трансформер от Google, часто не отличимый от привычной речи, без грубых, бросающихся в глаза ошибок.
«Обучить» языковую модель могут только создатели, добавляя новые настройки, но никак не пользователи рассказывая, что правильно, а что — нет. Бот лишён мотивации и воли, программа не понимает смысл, выдаёт противоречащие друг другу ответы, ошибается и не несёт ответственности за ошибку.






